今天我們將進行Pytorch中的第二個模型建立,並使用CIFAR-10資料集進行影像辨識。不過這樣聽起來有點單調,所以在今天的章節中,我將跟大家介紹如何建立一個屬於自己的訓練器,並在這個訓練器上定義優化方法。
而在本章節之後我們將會繼續使用這個訓練器進行模型的優化與調整,因此在本章節建立卷積神經網路時我們將會把損失函數的結果應用到前向傳播的結果中,並在前向傳播的傳入參數使用**kwargs的方式傳遞以符合訓練器的設定。
而我們今天的主要目的是告訴你在建立訓練器之前我們需要先了解在訓練模型時會發生的三件事情。並將這些方案融入到訓練器中,以完成卷積神經網路的訓練。
在我們訓練模型時第一件需要注意的事情過度擬合的解決與適應。由於我們很難配置一個完全符合資料集的模型,因此當模型訓練到後期,大多數情況下都會發生過度擬合的狀況。能夠完美收斂的模型非常罕見。因此我們需要找到一種方式來判斷模型在何時開始過度擬合,在下圖中展示了訓練時損失值與訓練周期之間的過度擬合現象。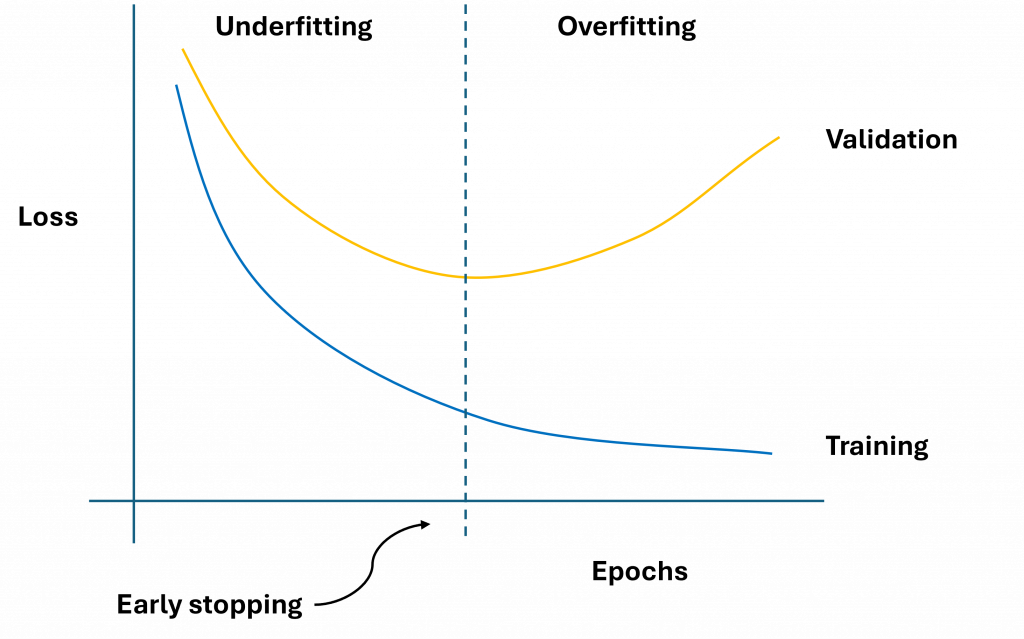
我們可以看到,在這個訓練曲線中應該在損失值最低的部分儲存該模型的權重,並中斷模型的訓練,因此為了解決這個問題我們需要使用提早停止(Early stopping)這一項技術。該作法是經過每訓練一個週期或一定步數(Step)後,透過驗證集來驗證當前模型的效能,如果驗證集的損失在一定的週期內不再下降則停止訓練。
第二件事情則是我們需要隨時儲存損失值最低的模型。這樣配合提早停止的策略,我們將能夠獲得最佳的模型,同時達成適時中斷訓練這兩項目標。如此一來,我們也可以減少對於週期超參數的設計,直接依賴提早停止即可。
提早停止這項技術特別依賴驗證資料集,若無驗證資料集或是驗證資料集過少,就很容易導致模型訓練效果比為加入此技術的狀態還差,因此該技術通常作用在有一定數量的資料集上時就會顯得比就有優勢。
第三件事情是我們要如何將損失值收斂到極限。由於我們的學習率都是相同的,因此在訓練過程中,如果陷入局部最優解,可能會因為動力不足而無法跳脫。而這種情況下我們應該增加學習率,使模型能夠脫離這個困境。因此我們需要一種能夠動態調整學習率的方法來優化模型,這個方法就叫做排程器(scheduler)。除了幫助模型跳脫局部最優解之外,這個方法的應用非常廣泛,可以確保模型收斂到全局最優點、幫助找出資料的特徵方向等等。而在今天我們要將此策略一次寫入到訓練器(Trainer)中,現在讓我們看一下以下步驟:
這次我們在初始化類別時,需要傳入以下參數:訓練次數(epochs)、訓練資料集(train_loader)、驗證資料集(valid_loader)、模型(model)、優化器(optimizer)、排程器(scheduler)、提前停止的週期數(early_stopping)、模型權重的儲存名稱(save_name)以及訓練所使用的裝置(device)。
而在這邊由於我們的模型可能是由多個架構組合而成,所以optimizer與scheduler實際上會被傳入一個容器型態,讓模型能夠各自更新。在device的部分,我們可以選擇自動判斷Pytorch版本是否能使用GPU進行運行,若能則自動抓取GPU進行訓練,或是讓使用者自行判斷是否要在CPU上運行或是使用GPU。保留這一點的彈性是因為在GPU上運行程式碼時,Pytorch有時會無法正確判斷錯誤的代號,因此我們有時需要手動轉換為CPU版本來進行除錯動作。
from tqdm import tqdm
import torch
import matplotlib.pyplot as plt
class Trainer:
def __init__(self, epochs, train_loader, valid_loader, model, optimizer, device = None, scheduler=None, early_stopping = 10, save_name = 'model.ckpt'):
# 總訓練次數
self.epochs = epochs
# 訓練用資料
self.train_loader = train_loader
self.valid_loader = valid_loader
# 優化方式
self.optimizer = optimizer # 優化器
self.scheduler = scheduler # 排程器(用於動態調整學習率)
self.early_stopping = early_stopping # 防止模型在驗證集上惡化
# 若沒輸入自動判斷裝置環境
if device is None:
self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
else:
self.device = device
# 宣告訓練用模型
self.model = model
# 模型儲存名稱
self.save_name = save_name
訓練時由於我們不清楚模型的訓練時間與進度,我們可以使用tqdm對train_loader進行包裝,以顯示這些資訊。並且我們在這裡需要特別注意一點,由於在模型的前向傳播時所需要的參數可能各不相同,因此我使用了**input_datas的方式,將輸入資料以**kwargs的方式傳入。在之後模型定義中,我會將第一個回傳值設為損失值,第二個則為前向傳播結果。因此,我們取出outputs[0]就能夠取得損失值,以進行反向傳播的計算。這樣子我們就寫出了一個叫通識化的訓練方法了。
def train_epoch(self, epoch):
train_loss = 0
train_pbar = tqdm(self.train_loader, position=0, leave=True) # 進度條
self.model.train()
for input_datas in train_pbar:
for optimizer in self.optimizer:
optimizer.zero_grad()
input_datas = {k: v.to(self.device) for k, v in input_datas.items()} # 將資料移動到GPU上
outputs = self.model(**input_datas) # 進行前向傳播
loss = outputs[0] # 取得損失值
loss.backward() # 反向傳播
# optimizer 可能有數個
for optimizer in self.optimizer:
optimizer.step()
# scheduler 可能有數個
if self.scheduler is not None:
for scheduler in self.scheduler:
scheduler.step()
postfix_dict = {'loss': f'{loss.item():.3f}'} # 定義進度條尾部顯示的資料
train_pbar.set_description(f'Train Epoch {epoch}') # 進度條開頭
train_pbar.set_postfix(postfix_dict) # 進度條結尾
train_loss += loss.item() # 加總損失值
return train_loss / len(self.train_loader) # 計算平均損失
同樣地,我們還需要一個驗證的函數。這個函數與我們前幾天撰寫的測試準確率的函數相似,只需要將訓練函數中包含梯度計算的部分全部移除即可。
def validate_epoch(self, epoch):
valid_loss = 0
valid_pbar = tqdm(self.valid_loader, position=0, leave=True)
self.model.eval() # 將模型轉換成評估模式
with torch.no_grad(): # 防止梯度計算
for input_datas in valid_pbar:
input_datas = {k: v.to(self.device) for k, v in input_datas.items()}
outputs = self.model(**input_datas)
loss = outputs[0]
valid_pbar.set_description(f'Valid Epoch {epoch}')
valid_pbar.set_postfix({'loss':f'{loss.item():.3f}'})
valid_loss += loss.item()
return valid_loss / len(self.valid_loader)
現在我們來實現提早停止的策略,在這裡我們需要進行三個主要動作,分別是:
stop_cnt 的參數。如果這個參數的數值超過了設定的閾值,就表示模型可能已經發生過度擬合的現象,此時我們就需要啟用提早停止策略。這三個步驟可以幫助我們在訓練過程中新快速定位最佳模型,同時避免過度擬合,提高模型的泛化能力,現在讓我們可以看到以下程式碼的撰寫方式。
def train(self, show_loss=True):
best_loss = float('inf')
loss_record = {'train': [], 'valid': []}
stop_cnt = 0
for epoch in range(self.epochs):
train_loss = self.train_epoch(epoch)
valid_loss = self.validate_epoch(epoch)
loss_record['train'].append(train_loss) # 加入訓練的平均損失
loss_record['valid'].append(valid_loss) # 加入驗證的平均損失
# 儲存最佳的模型
if valid_loss < best_loss:
best_loss = valid_loss
torch.save(self.model.state_dict(), self.save_name) # 儲存模型
print(f'Saving Model With Loss {best_loss:.5f}')
stop_cnt = 0
else:
stop_cnt += 1
# Early stopping
if stop_cnt == self.early_stopping:
output = "Model can't improve, stop training"
print('-' * (len(output) + 2))
print(f'|{output}|')
print('-' * (len(output) + 2))
break
print(f'Train Loss: {train_loss:.5f}', end='| ')
print(f'Valid Loss: {valid_loss:.5f}', end='| ')
print(f'Best Loss: {best_loss:.5f}', end='\n\n')
# 顯示訓練曲線圖
if show_loss:
self.show_training_loss(loss_record)
當我們取得驗證和訓練的損失值後,我們還需要建立一個繪製損失函數的方式,我們需要使用到 plt.plot 這個方法。這個方法會把我們儲存的數值轉換成 Y 軸的數值,並自動產生對應的 X 軸,然後將這些點連接起來形成折線圖。這樣一來我們能夠更直觀地了解在模型訓練過程中是否出現梯度爆炸(Gradient Explosion)和梯度消失(Gradient Vanishing)的問題。
梯度消失指的是在反向傳播過程中,誤差的梯度在每一層傳遞時,梯度逐漸變小最終趨於零,導致網路的權重無法有效更新。而梯度爆炸則是指在反向傳播過程中,梯度值隨著網路層數增加而變得越來越大,最終導致權重更新幅度過大,造成網路訓練發散,模型無法收斂。
梯度消失問題通常會發生在使用sigmoid或tanh激勵函數的神經網路中(當輸出值接近0時,梯度值會非常小),而梯度爆炸問題則常出現在激勵函數未對輸入進行有效限制的情況下發生。
def show_training_loss(self, loss_record):
train_loss, valid_loss = [i for i in loss_record.values()]
plt.plot(train_loss)
plt.plot(valid_loss)
# 標題
plt.title('Result')
# Y軸座標
plt.ylabel('Loss')
# X軸座標
plt.xlabel('Epoch')
# 顯示各曲線名稱
plt.legend(['train', 'valid'], loc='upper left')
# 顯示曲線
plt.show()
今天我們主要介紹了如何在 PyTorch 中建立一個訓練器。建立訓練器的原因是訓練時的步驟通常具備高度重複性,因此我們自行建立一個訓練器可以幫助我們縮短日後撰寫相同程式碼的時間,更能夠理解相關的優化策略,以防止模型過度擬合、儲存最佳模型,並動態調整學習率。最後我們還視覺化了損失變化,以便更好地理解模型的訓練過程。至於明天我會介紹如何建立模型的架構,讓你能夠使用這個訓練器進行模型的訓練與優化。
本文中的程式碼都放置在我的GitHub中:
Learning-AI-in-30-Days-by-Using-Math-for-Better-Understanding

